Outputting data and creating new datasets
There are usually two options when producing data from a program, you can either create a new data set / Unix file to send the data to, or add it to an existing file.
Outputting to existing datasets
When the DISP parameter in your DD statementis set to OLD, you have write access to the data set you have specified, and the outputted data will overwrite or replace the data set specified. If the DISP parameter is set to MOD, the data will be appended at the end of the current data set, instead of overwriting it.
Overwrite

This dataset will be completely overwritten
Append

This dataset will be appended to
Not enough space
A common issue when outputting data is that the data set we are trying to add to or overwrite might not have enough space to hold our data. This would cause the job to fail with the error SB37
Creating a new dataset
If you want to create a new file, you can specify the name of it with the DSN parameter and use the (NEW,CATLG) value for the DISP parameter.
Naming the new dataset
Keep in mind that the name you supply must be a maximum of 44 characters (35 for generation data sets) and you must be authorized to use the name that you supplied.
Unqualified names
Unqualified names of the data sets are simple 1-8 character strings.

Qualified names
Qualified names are multiple unqualified names joined by dots. You will most likely use qualified names.
For example
PROD.PEN.TRANS.SORTED

When creating a new dataset you might not always know how much space will you need, unless you're placing data on tape, you need to specify the SPACE parameter
Generation Data sets
If you want to simply create a new generation of an existing Generation data set and send the output to it, you can specify the name as usual, and use a +1 as the generation.

Temporary Data sets
Creating temporary data sets is also pretty simple. Temporary data set names begin with && followed by 1-8 character names. This can be coded as the DSN to indicate it's meant to be a temporary data set.

Another way of doing it is to not code a DSN parameter at all. In this case the system will name the temporary data set itself. This is nice if you don't need to reference the data set in later parts of the job.
DISP
It is kind of important to pay attention to the DISP parameter when creating new data sets
Where will the data set go?
When making a new data set it is important to know what type of device it will be on.
UNIT
When creating a data set the system will need to know what type of device it will be stored on.
You can specify the type of device that will be used to store the data set
CARTcan be used for a tape cartridgeSYSDAcan be used for a system disk (DASD)SYSALLDAis also a group referencing all DASD devices

You can be a bit more specific and specify the number for device types
UNIT=3390would be the device-type for commonly used for DASDUNIT=3400-5would be the device type commonly used for tape drives

You can code the device number (4 digit hex number) and need to have a slash before it as well
UNIT=/04DE

It is likely that the system administrator has put defaults in place so that something appropriate is selected if the parameter is not specified, but try to not forget it!
This can be used to define where the data set will go in broad strokes. VOL can be used for DASD devices and tape cartridges to define the name of a specific volume to use. This can be used for example when you want to send a set a data that will be sent to another org later on.
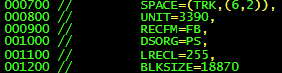
Space allocation for the new data set
SPACE
This is the parameter you need to specify in relation to how much space will your newly created data set use
The syntax for how this works is :
SPACE=(unit,(primary,secondary,dir))

Unit
Unit can have a few values
CYLfor cylindersSPACE=(CYL,(10,2))TRKfor tracksSPACE=(TRK,(8,1))- block length in bytes
SPACE=(200,(500,100))
Although tracks and cylinders are no longer used, they are still there for consistency.
Primary allocation
Primary is the amount of space unit to be allocated initially for the data set.
If you specify 10 tracks, the data set will instantly be allocated 10 tracks.
Secondary allocation
Secondary is the amount of data that the set is allowed to grow past the primary allocation, The system will allow up to 15 lots of the secondary extent to be defined if required making 16 overall. Those are only defined when needed.
In the example of SPACE=(CYL,(10,2)) the maximum amount of space that the data set can occupy is 10 + 15 * 2 cylinders, making the total 40.
Partitioned Data Sets
the DIR subparameter is only used for PDS and defined the number of directory blocks.
Those blocks contain the names of the members in the PDS and their location within the set.

If you use bytes as the measurement, you will need to specify the average record length as well, by adding the AVGREC parameter.
RLSE
RLSE can also be coded as the last subparameter.
This will instruct the system that space allocated for a new data set that is not used is to be released when the data set is closed. This is great for saving system space ,however it can create issues when trying to add to this data set later on, as it might not have enough space for that.

AVGREC
This parameter must be coded to to defined whether the number you supplied in the SPACE parameter is in Units U Kilobytes K or Megabytes M
In this example the average record size is 340 bytes, and the primary space is 5 * 1K = 5120 bytes.
This is because while tracks etc represent record quantities, bytes can come in multiple denominations.
You also need to provide information to the system regarding how data is read from and written to a data set
You can do this with the DCB parameter
DCB
This parameter should be used to give information about how data is read from and wrote to a data set
DCB=(DSORG=xx,RECFM=yy,LRECL=zzMBLKSIZE=nnn)
It takes a few sub parameters

You used to need to code all of those parameters as part of the DCB parameter, though you can now also code them individually
Copying from previous statement
As with a few others, you can copy them from a previous statement using the usual syntax

Importing from data set
If you need to create multiple data sets with the same DCB characteristics, you can save those in a data set and import it from it.

Subparameters
Data Set Organization
DSORG is the Data Set Organization, this defines the type of the data set
PS- Sequential data setPO- Partitioned Data setDA- Direct Access Data set
if you don't specify this, the system will attempt to guess.
Record Format
RECFM is Record Format, it is used to defined attributes associated with the records in the new data set
F- fixed length records that are not grouped to form a blockFB- fixed length records that are forming blocksV- variable length records that do not form blocksVB- variable length records that do form blocksU- undefined length
You might also addAto the end of those values to indicate that the records contain ANSI characters used for printing purposes
Logical Record Length
LRECL is the logical record length, it defines the length of records in the data set,.
The value should be in bytes. For variable length records it should be the longest record.
Sometimes when dealing with libraries, it might have the record format as U and Logical record length set to 0 because there is no logical record to be associated with a block.
Block Size
BLKSIZE is the block size and it is used to sepcify the size of the block of data in bytes, kilobytes, megabytes or gigabytes that is read from or written to.
Fixed length records
For fixed length records this should be a multiple of the LRECL.
For example fixed length records of 80 bytes with a block size of 800 would allow 10 records per block.
Variable length records
For variable length records this value should a be multiple of LRECL + 4 bytes to include the record descriptor word.
Zero value
If the block size is coded as 0 the system will determine the optimal block size based on the LRECL and the physical characteristics of the disk device.
Omitting the sub parameter will have the same result.
Copying parameters from another data sets
LIKE
If you are in a SMS managed environment and you know of a data set that you want to copy the attributes of, you can use the LIKE parameter to copy those attributes.

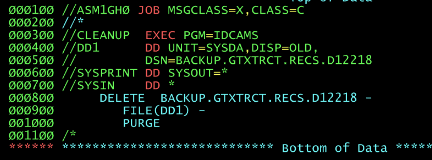
Retention period and expiration date
RETPD
This parameter specifies the Retention period for the data in the data set you're creating.
This might be useful for governance or regulatory purposes.
It is coded as a 5 digit field that specifies the number of days that the data in the data set should be retained for.
The maximum is 93000 days. The system will use this number against the current system date to determine the end of the retention period.

In this example the data set will be retained for 90 days
EXPDT
Expiration date can specify when the file should be deleted.
It is coded as a combination of year and day of year, for example
2025/032 will delete the file on the 32nd day of 2025 (which means February 1st)

A special values of 99365 and 99366 can be used to define a permanent retention
This can be helpful to prevent accidental deletion of the data sets, for example during the job. If an operator attempts to manually delete a file with a permanent expiration date, it they will need to manually override it in a confirmation window.
If you need to use JCL to delete a file protected by expiration date, you can use IDCAMS utility with a PURGE control statement
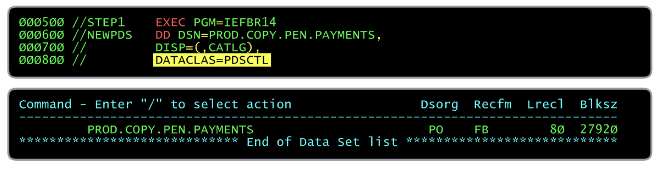
Simplifying with classes
You Many organizations will have SMS implemented, which also allows you to simplify some of your JCL, using SMS class parameters
DATACLAS
A data class can contain many of the DCB attributes discussed above, as well as retention and expiration periods.