DD Positional keywords
DSN / DSNAME
This parameter is used to specify the name of the data that the program will process.
It can be placed anywhere in the statement.
The syntax of it is pretty simple
DSNAME=IBMUSER.TEST.THING
The same syntax can be applied to PDS
DSN=IBMUSER.TEST.THING(MEMBER) to specify the member of the PDS
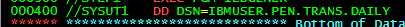
PATH
This parameter can be used to specify a z/OS UNIX file is to be used
For example
//NAME DD PATH=‚/u/ibmuser/testfile’
This is one of the few scenarios where you do not need to type in ALL CAPS, as unix file names are also case sensitive.
If your job uses a data set across several steps you might see this parameter referring to a previous step
DSN=*.STEP3.SYSUT2,DISP=SHR Where STEP3 is an EXEC statement of the previous step and SYSUT2 is a DD statement within that step.
This will use the same data set, which can be handy, for example when you’d need to update the data set used, now you’d only need to update it once and the rest would be resolved automatically.

DISP
This parameter Describes the disposition or the status of the data set.
It normally has three subparameters that describe the following
- The status of the data (does it exist, is it used exclusively)
- How is the data set to be handled after the step completes successfully
- How is the data set to be handled on a failed step
In many cases (for example when a data set is used for input) you will not need to do anything special in either success or failure. In this case you can just provide the first subparameter and leave the other ones to go to default (which is KEEP, keeping the file)
The first subparameter
The first subparameter will indicate the status of the data set that is to be used:
- SHR - Share, the data set should be handled in a shared way, this is essentially a read-only access to the data, as many programs can use it at the same time
- OLD - Exclusive, this program is the only one that will use the dataset, it can then perform operations like writing (which would not be possible when multiple programs would be accessing the file)
- MOD - This will also allow operations like writing, however it will also instruct the system to append anything written to the file at the end of it, instead of overwriting the data set like it would do with OLD
- NEW - This means that the data set is to be created for the use in this program. This is the default if the first subparameter is not coded
The second subparameter
The second subparameter tells how to handle the data set after the step completes with success:
- CATLG - the data set is retained and an entry is placed in the catalog so it can be easily located
- KEEP - In SMS environments KEEP implies CATLG because SMS needs to know all data sets on the system. In a NON-SMS env the data will be retained but there won't be a catalog entry created for it, which can make it harder to find later on. If generation dat aset s are referncing the relative generation numbers this value won't result in data set being cataloued, only kept.
- PASS - the data set will be passed to the next step of the job, this is commonly used for temporary data sets.
- DELETE - the data set is not longer needed after the step and will be removed
If you omit this parameter for a new data set, the default will be DELETE.
If you omit it for an existing data set, KEEP will be the default.
The Third subparameter
This one will determine what happens to the data set when the step fails
For the third subparameter, all values except of PASS are allowed from the second subparameter.
If omitted, the default is what will be specified or implied for the second one, except if it is PASS, this would make the default same as the second.
New data sets
When creating a new file you can use the (NEW,CATLG) value for the parameter.
In scenarios where the DISP parameter is not coded in at all the (NEW,DELETE,DELETE) default will be used, pretty sure making a temporary file just for the processing of it, and it might create errors too.
See Outputting data and creating new datasets for more!
PATHOPTS
This atramentem can be used the access type and status of the file when dealing with z/OS UNIX files. IT is kind of the same thing as DISP parameter in the world of UNIX files.
If not specified the system will assume that the file exists and will look for it (and fail if the file does not exist)
For a file that is used for input purpose only a value of ORDONLY should be used
PATHOPTS=ORDONLY
PATHMODE
This parameter is used to assign file attributes to the file being created
PATHDISP
This parameter instructs the system on the action to be taken with the specified z/OS UNIX file: on successful completion and on failure. Pretty much a DISP for the UNIX files.
DLM
This can be used to determine what the delimiter should be when processing in-stream data
For example
DLM=‚$$’ will mean that the following in-stream data will be parsed until the $$ symbol is found on a new line.
//NAME DD DATA,DLM=‚$$’
Could be followed by the raw in-stream data then.
UNIT
When creating a data set the system will need to know what type of device it will be stored on.
You can specify the type of device that will be used to store the data set
CARTcan be used for a tape cartridgeSYSDAcan be used for a system disk (DASD)SYSALLDAis also a group referencing all DASD devices

You can be a bit more specific and specify the number for device types
UNIT=3390would be the device-type for commonly used for DASDUNIT=3400-5would be the device type commonly used for tape drives

You can code the device number (4 digit hex number) and need to have a slash before it as well
UNIT=/04DE

It is likely that the system administrator has put defaults in place so that something appropriate is selected if the parameter is not specified, but try to not forget it!
VOL
This parameter performs a similar function to UNIT, it can be used for DASD but is more commonly used for tape cartridges and allows you to define the name of the specific volume to be used
VOL=SER=TX2018
It can also refer back to a previous statement to use the same volume that was defined there.
VOL=*.STEP1.SYSUT2
If the specified volume is not available, the operator will receive a prompt to take action (specify another one or cancel the job)
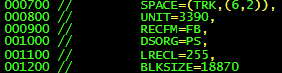
SPACE
This is the parameter you need to specify in relation to how much space will your newly created data set use
The syntax for how this works is :
SPACE=(unit,(primary,secondary,dir))

Unit
Unit can have a few values
CYLfor cylindersSPACE=(CYL,(10,2))TRKfor tracksSPACE=(TRK,(8,1))- block length in bytes
SPACE=(200,(500,100))
Although tracks and cylinders are no longer used, they are still there for consistency.
Primary allocation
Primary is the amount of space unit to be allocated initially for the data set.
If you specify 10 tracks, the data set will instantly be allocated 10 tracks.
Secondary allocation
Secondary is the amount of data that the set is allowed to grow past the primary allocation, The system will allow up to 15 lots of the secondary extent to be defined if required making 16 overall. Those are only defined when needed.
In the example of SPACE=(CYL,(10,2)) the maximum amount of space that the data set can occupy is 10 + 15 * 2 cylinders, making the total 40.
Partitioned Data Sets
the DIR subparameter is only used for PDS and defined the number of directory blocks.
Those blocks contain the names of the members in the PDS and their location within the set.

If you use bytes as the measurement, you will need to specify the average record length as well, by adding the AVGREC parameter.
RLSE
RLSE can also be coded as the last subparameter.
This will instruct the system that space allocated for a new data set that is not used is to be released when the data set is closed. This is great for saving system space ,however it can create issues when trying to add to this data set later on, as it might not have enough space for that.

AVGREC
This parameter must be coded to to defined whether the number you supplied in the SPACE parameter is in Units U Kilobytes K or Megabytes M
In this example the average record size is 340 bytes, and the primary space is 5 * 1K = 5120 bytes.
This is because while tracks etc represent record quantities, bytes can come in multiple denominations.
DCB
This parameter should be used to give information about how data is read from and wrote to a data set
DCB=(DSORG=xx,RECFM=yy,LRECL=zzMBLKSIZE=nnn)
It takes a few sub parameters

You used to need to code all of those parameters as part of the DCB parameter, though you can now also code them individually
Copying from previous statement
As with a few others, you can copy them from a previous statement using the usual syntax

Importing from data set
If you need to create multiple data sets with the same DCB characteristics, you can save those in a data set and import it from it.

Subparameters
Data Set Organization
DSORG is the Data Set Organization, this defines the type of the data set
PS- Sequential data setPO- Partitioned Data setDA- Direct Access Data set
if you don't specify this, the system will attempt to guess.
Record Format
RECFM is Record Format, it is used to defined attributes associated with the records in the new data set
F- fixed length records that are not grouped to form a blockFB- fixed length records that are forming blocksV- variable length records that do not form blocksVB- variable length records that do form blocksU- undefined length
You might also addAto the end of those values to indicate that the records contain ANSI characters used for printing purposes
Logical Record Length
LRECL is the logical record length, it defines the length of records in the data set,.
The value should be in bytes. For variable length records it should be the longest record.
Sometimes when dealing with libraries, it might have the record format as U and Logical record length set to 0 because there is no logical record to be associated with a block.
Block Size
BLKSIZE is the block size and it is used to sepcify the size of the block of data in bytes, kilobytes, megabytes or gigabytes that is read from or written to.
Fixed length records
For fixed length records this should be a multiple of the LRECL.
For example fixed length records of 80 bytes with a block size of 800 would allow 10 records per block.
Variable length records
For variable length records this value should a be multiple of LRECL + 4 bytes to include the record descriptor word.
Zero value
If the block size is coded as 0 the system will determine the optimal block size based on the LRECL and the physical characteristics of the disk device.
Omitting the sub parameter will have the same result.
LIKE
If you are in a SMS managed environment and you know of a data set that you want to copy the attributes of, you can use the LIKE parameter to copy those attributes.

RETPD
This parameter specifies the Retention period for the data in the data set you're creating.
This might be useful for governance or regulatory purposes.
It is coded as a 5 digit field that specifies the number of days that the data in the data set should be retained for.
The maximum is 93000 days. The system will use this number against the current system date to determine the end of the retention period.

In this example the data set will be retained for 90 days
EXPDT
Expiration date can specify when the file should be deleted.
It is coded as a combination of year and day of year, for example
2025/032 will delete the file on the 32nd day of 2025 (which means February 1st)

A special values of 99365 and 99366 can be used to define a permanent retention
This can be helpful to prevent accidental deletion of the data sets, for example during the job. If an operator attempts to manually delete a file with a permanent expiration date, it they will need to manually override it in a confirmation window.
If you need to use JCL to delete a file protected by expiration date, you can use IDCAMS utility with a PURGE control statement
DATACLAS
A data class can contain many of the DCB attributes discussed above, as well as retention and expiration periods.
MGMTCLAS
This class can be used to define the details of how the data set should be migrated between different storage mediums

STORCLAS
Storage class can be used to replaec teh UNIT and VOL parameters

DSNTYPE
This parameter also can make things easier for us. It can differentiate between a regular PDS and a PDSE, a z/OS Unix named pipe, basic, large and extended format data sets.

SYSOUT
This parameter in its simplest form is used to assign a class to output directed to that DD statement. Classes and their attributes are defined during JES initialization and any deviation from those are shown as overrides of the defaults.

The value of this parameter should be a valid JES class, however it can also be an asterisk *
When this happens, the class will be taken from the MSGCLASS JOB Positional parameters
This parameter can also take a few sub parameters to alter how it works. Those parameters are positional so you need a comma to skip them.

Writer-name
An external writer may be required to process the sysout that cannot be handled by JES. For example to esnd the data to a specific printer or data set not supported by JES

Form-name
If the sysout needs to be printed on a specific type of form, then you can specify a 1-4 character form name to be used. Once created it can only be printed when a printer definition has been configured to process that specific form name and class.

INTRDR
This instructs the system to use the sysout as an input job stream.
This can be used when your job creates some customized JCL to submit it to the internal reader (hence the name)

Code-name
The code name is used if you need to reference an earlier JES2 /*OUTPUT statement. If the name is not the name of one, the system will assume that it is a form name.
Nullification
you might encounter a situation where you have to code a SYSOUT statement but you need to nullify a sysout data set. You can just assign nothing or (,) to the parameter
COPIES
If you want to print multiple copies of a SYSOUT, you can specify the number of copies you want to print with this parameter

DEST
Normally when you create a output with just SYSOUT parameter, it would be sent to the default destination for the input device. This is usually suitable, but you can also redirect it to another destination with this parameter.
it takes few different types of values
- LOCAL
- The local node on a local node
- name
- This can be any installation specific name defined during JES2 initialization
- node
- This is used to specify the node that the output is being sent to. The syntax for specifying this is
Nnnnnn. So N1 would be the node number one that was defined during initialization
- This is used to specify the node that the output is being sent to. The syntax for specifying this is
- node and remote
- There are a few ways of specifying this but it boils down to
N**R**where the number after the N is the node number and the number after the R is the remote number. Up to six numbers can be combined to create this destination
- There are a few ways of specifying this but it boils down to
- remote
- This can specify a defined remote destination with
R12312(numbers preceded by R)
- This can specify a defined remote destination with
- (node,userid)
- This format can be used to send output ot a TSO user, or a VM user at a specified node
- userid
- This can be used to send output to a specified user
- U12312
- this notation (numbers preceded by U) can be used to send the ouput t oa local terminal that has special routing.
OUTLIM
Sometimes you need to curb the enthusiasm of the output and limit how long it can be.
You can use the OUTLIM parameter to limit the maximum amount of records to be produced in the sysout data set before the system limit exit routine is called.
in most cases this will result in the job being terminated with the 722 system code

HOLD
You can use this parameter to place a hold on sysout.
You might want to do this for a few reasons
- The output needs to be printed and should be inspected by a real person beforehand
- The output is very large and you don't want it to take over the printer for a long time when it is needed
- It needs a special form that might not be always handy
It has a very simple syntax with the value ofYESholding the output and the default ofNOnot doing that
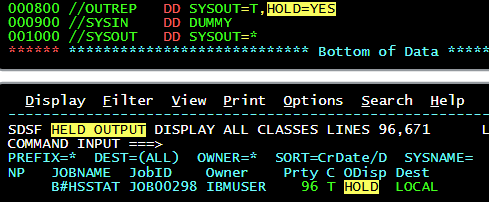
FREE
If the output is to be printed the system will normally wait until the job has completed and then attempt to find an available printer.
If you have a job that runs for a very long time, you can use
FREE=CLOSE parameter which will un-allocate the sysout data set when it is closed.
This will let the output to be considered for printing immediately after it is closed, not after the job has finished
